資訊內(nèi)容
介紹python爬取網(wǎng)頁(yè)
 3SL少兒編程網(wǎng)-https://www.pxcodes.com
3SL少兒編程網(wǎng)-https://www.pxcodes.com之前在網(wǎng)上也寫(xiě)了不少關(guān)于爬蟲(chóng)爬取網(wǎng)頁(yè)的代碼,**近還是想把寫(xiě)的爬蟲(chóng)記錄一下,方便大家使用吧!3SL少兒編程網(wǎng)-https://www.pxcodes.com
代碼一共分為4部分:3SL少兒編程網(wǎng)-https://www.pxcodes.com
第一部分:找一個(gè)網(wǎng)站。3SL少兒編程網(wǎng)-https://www.pxcodes.com
我這里還是找了一個(gè)比較簡(jiǎn)單的網(wǎng)站,就是大家都知道的https://movie.douban.com/top250?start= 大家可以登錄里面看一下。這里大家可能會(huì)有一些庫(kù)沒(méi)有進(jìn)行安裝,先上圖讓大家安裝完爬取網(wǎng)頁(yè)所需要的庫(kù),其中我本次用到的庫(kù)有:bs4,urllib,xlwt, re。3SL少兒編程網(wǎng)-https://www.pxcodes.com
(免費(fèi)學(xué)習(xí)推薦:python視頻教程)3SL少兒編程網(wǎng)-https://www.pxcodes.com
如圖3SL少兒編程網(wǎng)-https://www.pxcodes.com
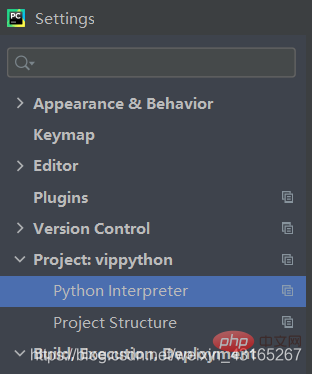
這里選擇file-setting-Project-然后選擇左下角的加號(hào),自行去安裝自己所需要的文件就可以了。3SL少兒編程網(wǎng)-https://www.pxcodes.com
下面的代碼是爬取網(wǎng)頁(yè)的源代碼:3SL少兒編程網(wǎng)-https://www.pxcodes.com
import urllib.requestfrom bs4 import BeautifulSoupimport xlwtimport redef main(): # 爬取網(wǎng)頁(yè) baseurl = 'https://movie.douban.com/top250?start=' datalist = getData(baseurl) savepath = '豆瓣電影Top250.xls' # 保存數(shù)據(jù) saveData(datalist,savepath) # askURL("https://movie.douban.com/top250?start=1")#影片詳情的規(guī)則findLink = re.compile(r'<a class="" href="(.*?)">') #創(chuàng)建從正則表達(dá)式,表示規(guī)則findImgSrc = re.compile(r'<img.*src="(.*?)"', re.S) #讓換行符匹配到字符中#影片的片名finTitle = re.compile(r'<span class="title">(.*)</span>')#影片的評(píng)分findReating = re.compile(r'<span class="rating_num" property="v:average">(.*)</span>')#找到評(píng)價(jià)人數(shù)findJudge = re.compile(r'<span>(d*)人評(píng)價(jià)</span>')#找到概況findInq = re.compile(r'<span class="inq">(.*)</span>')#找到影片的相關(guān)內(nèi)容findBb = re.compile(r'<p class="">(.*?)</p>', re.S)#re.S忽視換行符第二部分:爬取網(wǎng)頁(yè)。3SL少兒編程網(wǎng)-https://www.pxcodes.com
def getData(baseurl): datalist = [] for i in range(0, 10): url = baseurl + str(i*25) html = askURL(url) #保存獲取到的網(wǎng)頁(yè)源碼 #對(duì)網(wǎng)頁(yè)進(jìn)行解析 soup = BeautifulSoup(html, 'html.parser') for item in soup.find_all('p', class_="item"): #查找符合要求的字符串 形成列表 #print(item) #測(cè)試查看電影信息 data = [] item = str(item) link = re.findall(findLink, item)[0] #re庫(kù)用來(lái)查找指定的字符串 data.append(link) imgSrc = re.findall(findImgSrc, item)[0] data.append(imgSrc) #添加圖片 titles = re.findall(finTitle, item) # if (len(titles) == 2): ctitle = titles[0] #添加中文名 data.append(ctitle) otitle = titles[1].replace("/", "") #replace("/", "")去掉無(wú)關(guān)的符號(hào) data.append(otitle) #添加英文名 else: data.append(titles[0]) data.append(' ')#外國(guó)名字留空 rating = re.findall(findReating, item)[0] #添加評(píng)分 data.append(rating) judgeNum = re.findall(findJudge,item) #評(píng)價(jià)人數(shù) data.append(judgeNum) inq = re.findall(findInq, item) #添加概述 if len(inq) != 0: inq = inq[0].replace(".", "") #去掉句號(hào) data.append(inq) else: data.append(" ") #留空 bd = re.findall(findBb,item)[0] bd = re.sub('<br(s+)?/>(s+)?',' ', bd) #去掉br 后面這個(gè)bd表示對(duì)bd進(jìn)行操作 bd = re.sub('/', ' ', bd) #替換/ data.append(bd.strip()) #去掉前后的空格strip() datalist.append(data) #把處理好的一部電影放入datalist當(dāng)中 return datalist第三部分:得到一個(gè)指定的url信息。3SL少兒編程網(wǎng)-https://www.pxcodes.com
#得到指定的一個(gè)url網(wǎng)頁(yè)信息def askURL(url): head = { "User-Agent": "Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.141 Mobile Safari/537.36"} request = urllib.request.Request(url,headers=head) # get請(qǐng)求不需要其他的的,而post請(qǐng)求需要 一個(gè)method方法 html = "" try: response = urllib.request.urlopen(request) html = response.read().decode('utf-8') # print(html) except Exception as e: if hasattr(e,'code'): print(e.code) if hasattr(e,'reason'): print(e.reason) return html第四部分:保存數(shù)據(jù)3SL少兒編程網(wǎng)-https://www.pxcodes.com
# 3:保存數(shù)據(jù)def saveData(datalist,savepath): book = xlwt.Workbook(encoding="utf-8", style_compression=0) sheet = book.add_sheet('豆瓣電影Top250', cell_overwrite_ok=True) col = ('電影詳情鏈接', '圖片鏈接', '影片中文名', '影片外國(guó)名', '評(píng)分', '評(píng)價(jià)數(shù)', '概況', '相關(guān)信息') for i in range(0,8): sheet.write(0,i,col[i]) #列名 for i in range(0,250): print("第%d條"%i) data = datalist[i] for j in range(0,8): sheet.write(i+1,j,data[j]) book.save(savepath) #保存這里大家看一下代碼,關(guān)于代碼的標(biāo)注我寫(xiě)的還是挺清楚的。3SL少兒編程網(wǎng)-https://www.pxcodes.com
其中關(guān)于學(xué)習(xí)這個(gè)爬蟲(chóng),還需要學(xué)習(xí)一些基本的正則表達(dá)式,當(dāng)然python基本的語(yǔ)法是不可少的希望對(duì)大家有幫助吧。3SL少兒編程網(wǎng)-https://www.pxcodes.com
相關(guān)免費(fèi)學(xué)習(xí)推薦:python教程(視頻)
以上就是介紹python爬取網(wǎng)頁(yè)的詳細(xì)內(nèi)容,更多請(qǐng)關(guān)注少兒編程網(wǎng)其它相關(guān)文章!3SL少兒編程網(wǎng)-https://www.pxcodes.com

- 上一篇

python中import如何使用
簡(jiǎn)介使用python中import的方法:1、【importmodule_name】,即import后直接接模塊名;2、【frompackage_nameimportmodule_name】把模塊組成的集合。本教程操作環(huán)境:windows7系統(tǒng)、python3.9版,DELLG3電腦。使用python中
- 下一篇

python輸入一個(gè)數(shù)n如何判斷是否為素?cái)?shù)
簡(jiǎn)介python輸入一個(gè)數(shù)n判斷是否為素?cái)?shù)的方法:1、利用for循環(huán)和break語(yǔ)句,代碼為【foriinrange(2,k+2):ifm%i==0:break】;2、利用while循環(huán)和bool變量。本教程操作環(huán)境:windows7系統(tǒng)、python3.9版,DELLG3電腦。python輸入一個(gè)數(shù)n
相關(guān)資訊
